Self-Driving with High Level Commands
Branched Architecture Self-Driving using Imitation Learning
Tyler Yep • Aug 04 2019
Introduction
I took CS 231N: Convolutional Neural Networks for Visual Recognition during the Spring quarter of my 3rd year at Stanford, and had the opportunity to work on a project with my friend Woody.
Our project was on Branched Architecture Self-driving using Imitation Learning (affectionately called BASIL). The basic problem we wanted to solve was how to train a network to drive a car in a simulator using high-level human input.
 Intersection Course
Intersection Course
High Level Commands
In a self-driving scenario, we want to be able to supply high-level commands to a car, and then have the car flawlessly execute those commands without human guidance. For example, if I am in a self-driving car, I might want the car to take the next available left turn. We emphasize that these must be “high-level” commands because the car may not need to turn left immediately; it may continue straight for a few miles before the first available left turn appears. Or, it may need to sharply turn left at that instant in order to complete the turn.
Thus, the challenge is figuring out how to allow a network to take in this high-level command as input and perform the correct actions over the correct time interval.
This problem is difficult because, given an image of an intersection, there are several possible “correct” answers for actions to take. For example, the car could turn the steering wheel right, left, or not change the steering wheel angle at all. However, if a car only accepts a single image as input, how does it know which of the three actions it should do?
This means that it is not enough for a car to be able to predict the action for the next time step - it must also be able to keep track of where it wants to go and execute these actions over a given timeframe.
Udacity Car Simulator
To simulate our solution to the problem, we adapted the Udacity Self-Driving Car Simulator, built for Udacity’s Self-Driving Nano-degree course. The vanilla simulator provides a simple interface to drive the car and save a recording. The recordings are saved as a series of RGB images along with labels of the current throttle and steer angle. The images are taken from 3 cameras on the car - a left-view, a center-view, and a right-view.
 Modified Udacity Simulator
Modified Udacity Simulator
The simulator was originally designed to solve the lane-following problem - to see if students could create a model to follow a simple road and train the car to stay within its lane. We built on top of the basic lane-following model in order to accomplish our new task. Below, we see the original Lake Track provided by the simulator, and compare it to the custom Intersection Track we built from scratch to provide a testing environment for our model.
 Modified Udacity Simulator
Modified Udacity Simulator
Intersection Track
The custom track we designed comprises of a grid-world of identical intersections. The only difference between the intersections is the trees and hills in the background. We trained our model in this world by simply driving around the world and noting the keypress whenever we were about to take a certain action.
We intentionally simplified the world in order to create a working proof-of-concept in our short project timeframe. In a real-world setting, we would want a wide variety of turns to train on; however, as a first step, our project intended to see what kinds of architectures would be successful in accomplishing the task.
Dataset
After driving around our test tracks and labeling the high-level intent at each intersection, we had a dataset of 200,000 images from the car’s cameras, each labeled with the intended action we were about to take. Our train/val/test split is 90%/5%/5%.
We also augment our data by randomly choosing the images from one of the three camera angles and then readjusting the steer angle based on the angle of the camera, which helps our car to readjust itself in the event that it veers into an unseen road position.
To prevent data imbalance (the dataset contains very few “turn” images, since turns are so brief), we ensure a minimum number of images mid-turn per mini-batch to balance the distribution.
Nvidia’s Conditioned Model
Nvidia’s baseline model consists of several sets of Convolutional layers followed by several feed-forward layers, funneled into a single output: steer angle. We can add a second output (throttle) by increasing the dimensions of the output tensor, but this performs terribly because of the aforementioned issue: given an image of an intersection, there are several possible “correct” answers for actions to take.
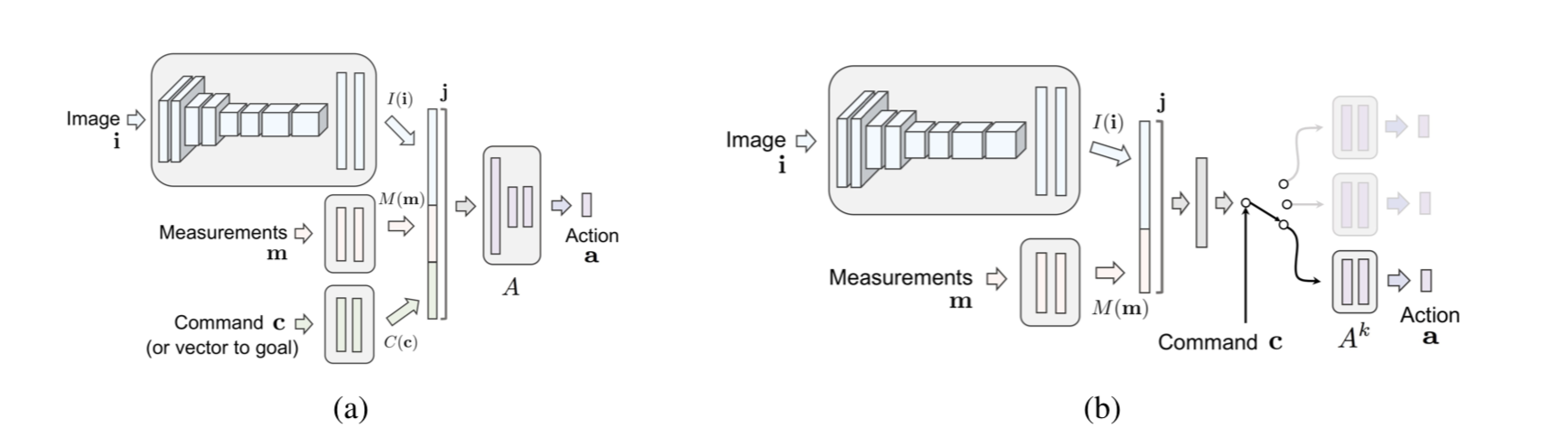
Nvidia-Branched Model
We added our desired branching structure inspired by Codevilla et al. to the Nvidia architecture:
 Modified Nvidia Model
Modified Nvidia Model
We train three separate final layers and set that to be the output of the Nvidia model, and then our network decides which final layer to use/train based off of a single high-level command feature.
ResNet with Branching
Finally, we tried the same branching architecture using ResNet-18 and ResNet-34, pretrained on ImageNet. We found that the ResNets outperformed the Nvidia models by a wide margin, with the ResNet-18 performing best on the held-out validation and test sets. We observe that the ResNet-34 performs worse because of the latency from making a prediction to outputting control to the simulator. For this reason, the ResNet with fewer parameters works much better.
| Intersection Track Results | # of Trainable Parameters |
|---|---|
| Nvidia-Conditioned | 252,244 |
| Nvidia-Branched | 493,994 |
| ResNet18-Branched | 11,769,414 |
| ResNet34-Branched | 21,877,574 |
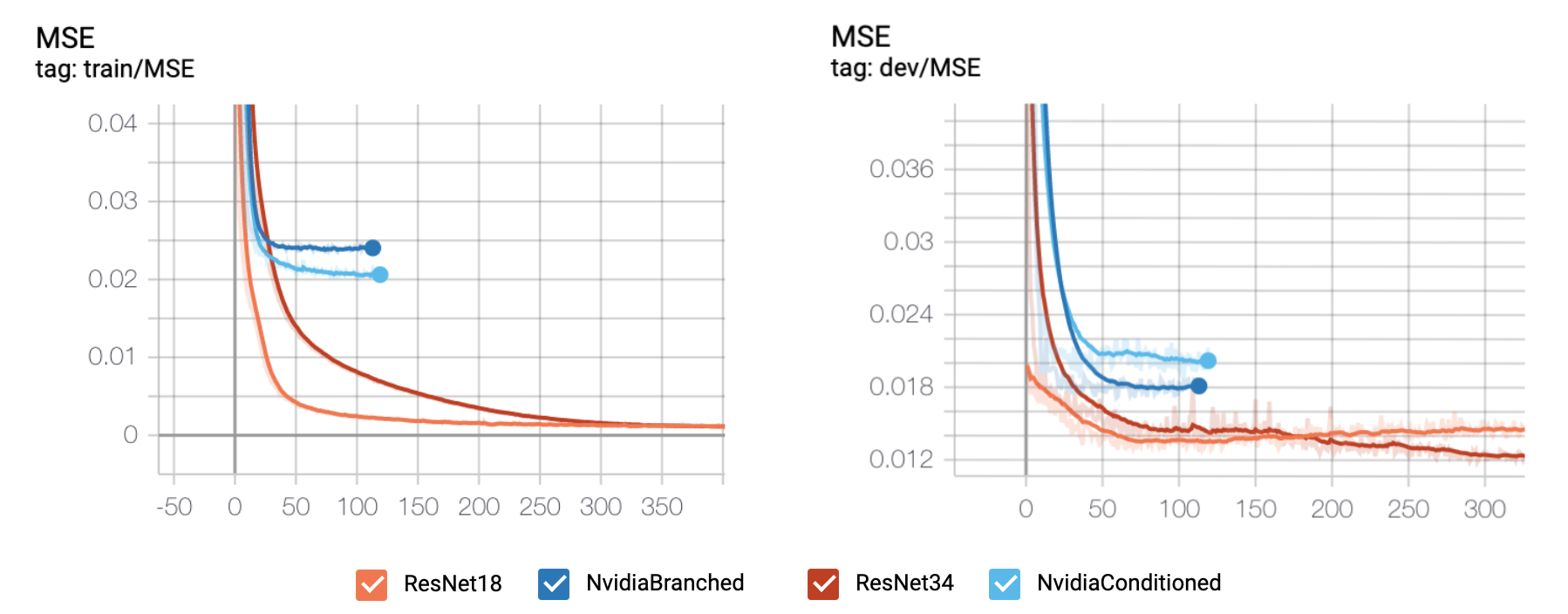 Training & Validation Curves
Training & Validation Curves
Analysis
To further analyze our network, we looked at activation maps and adversarial examples.
Activation Maps
Activation maps were crucial for ensuring our network is properly learning. For a long time, our network was giving us terrible results but a low MSE. We realized that we were using torch.view(…) instead of torch.permute(…). ☹
 Activation Maps
Activation Maps
-
In the left image, the vehicle is about to complete a right turn. From the activation of the image and input high-level control (turn right), we see the corner of the intersection highlighted, indicating that the model is attending to the corner point, likely to avoid hitting it.
-
In the center image, we see the outlines of the crosswalk lines in the activation map. Most of the activation maps of our crosswalks show a clear outline of all of the crosswalk stripes. However, in this picture, we see that the right lane of the crosswalk is the brightest part of the map. From this activation map, we see that the network is attending to the right lane as the location to drive towards and the way to stay in its lane.
-
In the right image, the network is paying attention to the lane lines and is driving straight. However, we also see that the brightest activation is in the right corner: a tree in the distance. This is a potential weakness with our model, since we want the model to identify that the most important parts of this image are the lane lines, not a tree in the background.
Adversarial Examples
In order to examine the vulnerability of our final ResNet18-Branched model, we generated adversarial images that would make our model steer drastically to the right or left when the intended control would be to not steer at all to stay within the lane.
 Adversarial Examples
Adversarial Examples
To create these adversarial examples, we began with an input image with a near-zero predicted steer and updated the image with the positive (steer right) or negative (steer left) gradient of the image with respect to the output steer. We repeatedly update the image until the predicted steer was above the target adversarial steer.
Conclusion
Overall, we found that our final ResNet18-Branched model drove the most smoothly and safely based on our evaluation metrics (# of curb collisions, drifts out of lane, etc.). In our simulator, the model with a branched architecture successfully navigates intersections in our grid world using high-level controls, which showcases our model’s ability to imitate expert driving and learn the correct starting and stopping times for maneuvers without any temporal information.
You can find our code at: